Wide & Deep Learning for Recommender Systems
文章来自于Google,提出结合了Wide模型和Deep模型的方法,来提升推荐效果;该网络模型应用于Google play的app推荐。
首先,文章开头提到Generalization和Memorization
- Generalization
对于大规模的回归或者分类问题:线性模型+非线性特征;输入比较稀疏,而且需要更多的特征工程。 为了减少人工构建特征,deep neural networks往往能从低维的稀疏特征,学习到高阶的特征;也就是文章中的Deep部分。
- Memorization Memorization 部分更多的是,特征交叉,效果较好,而且可解释性强,比如
AND(user_installed_app=netflix, impression_app=pandora”), whose value is 1
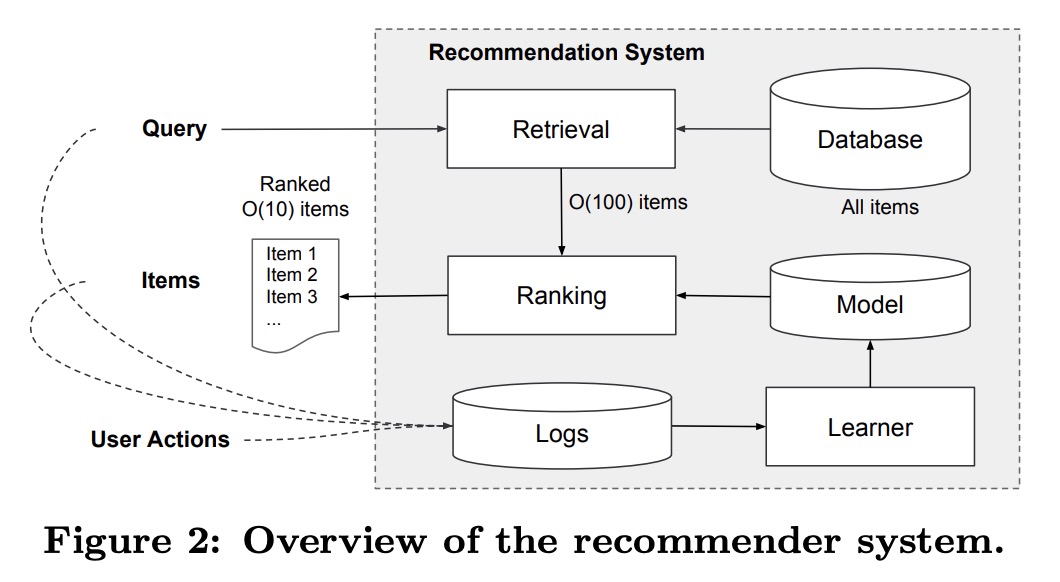
recommender system
完整的推荐系统流程:
- query :查询,包括用户信息,以及上下文信息
- retrieval: 检索,根据query内容,返回相应匹配的list of items,这里的数量级在O(100)。
- ranking:根据检索到的list of items,作一个排序,本文的重要主要在于给这些items评分,然后排序
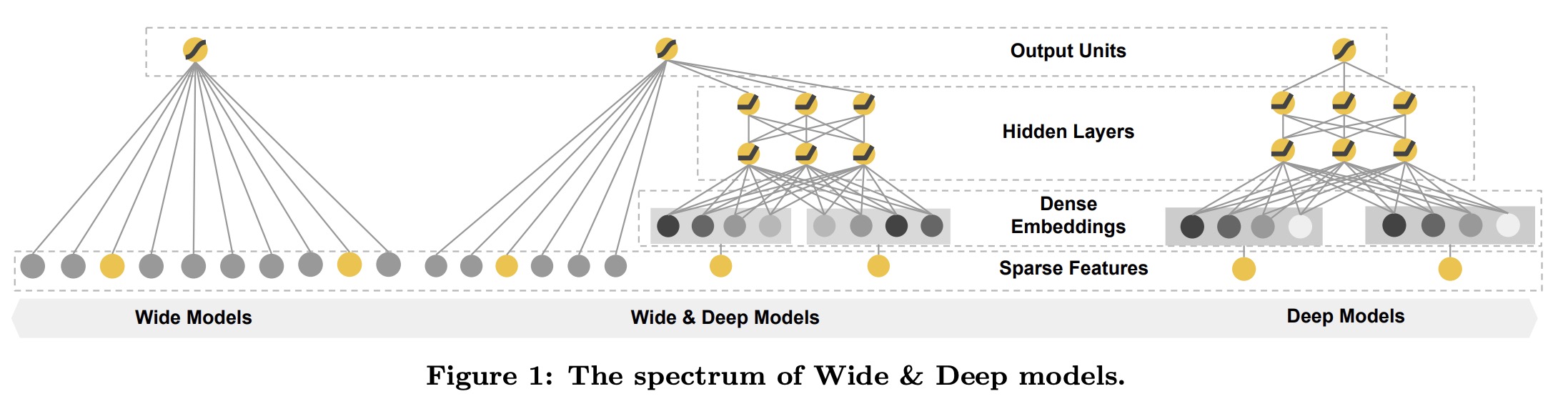
Wide Component
wide部分也就是上图左边部分,也就是广义线性模型部分;
\[y=w^Tx+b\]组合特征部分:
\[\phi_k(x)=\prod_{i=1}^{d}x_i^{c_{ki}} \qquad c_{ki} \in \{0,1\}\]这里的\(c_{ki}\)表示第i个特征是否参与第k个组合特征。
i表示输入x的第i维。
(e.g.,“AND(gender=female, language=en)”) is 1 if and only if the constituent features (“gender=female” and “language=en”) are all 1, and 0 otherwise
Deep Component
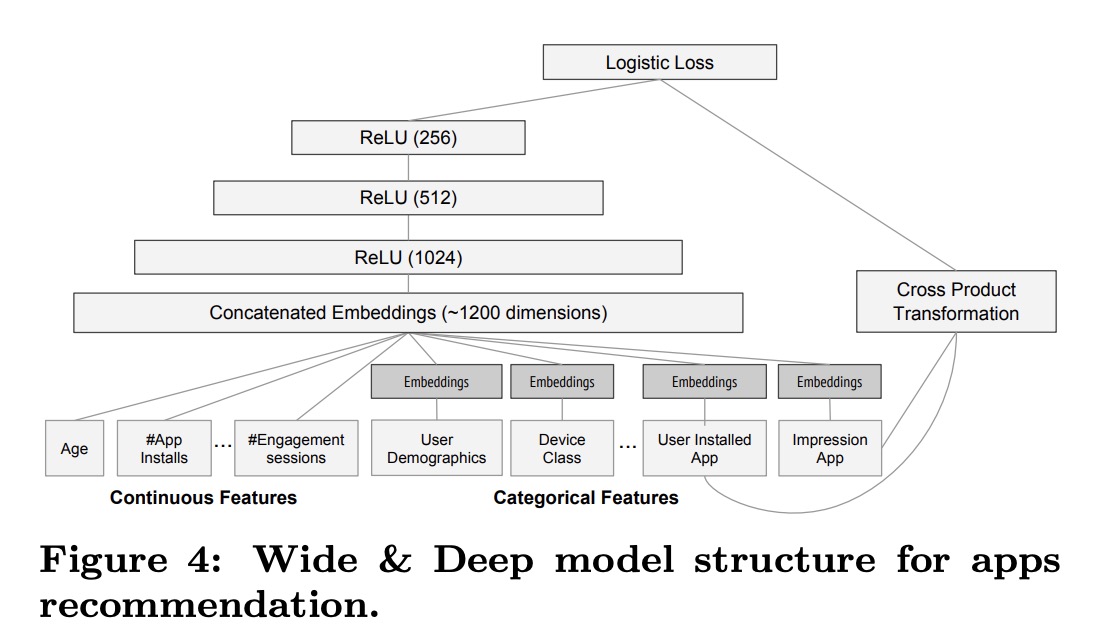
Deep,也就是上图的右边部分;首先把低维的输入特征转化为embedding vector。embedding vector的维度在O(10)~O(100)之间。论文里提到,这些vector初始化阶段是随机的。
Joint Training of Wide & Deep Model
合并 wide & deep,2部分输出结果相加再输入logistic loss。
optimizer
wide采用Followthe-regularized-leader (FTRL)优化算法
deep则用AdaGrad。
网络最终的输出:
\[P(Y=1|x)=(w^T_{wide}[x,\phi(x)]+w^T_{deep}a^{(l_f)}+b)\]Data Generation
数据预处理部分,对于categorical feature 转化为字典; 连续值则作n切分,并且归一化;
Model Serving
实际在生产环境中,对于检索系统返回的 app list。采用多个小的batch,并行计算score,从而保证服务的实时性。
这篇论文不长,论述也很清晰。
参考
1、Wide & Deep Learning for Recommender Systems