Deep Interest Network for Click-Through Rate Prediction
一篇来自阿里妈妈团队的paper,关于提升广告系统的CTR。
近年来,Deep learning在NLP和CV领域的很多应用都取得了State-of-the-art的效果。同样地在CTR预估方面,也有所尝试,比如wide&deep、Embedding&MLP。
Embedding&MLP
大量的稀疏输入特征被转化为低维度的embedding vectors。再拼接成固定大小的vectors,然后是全链接层(通常是MLP 也就是多层感知机)。相比于传统的LR模型。省去人工构建特征的工作量,使得模型的拟合能力更加强大,并取得良好的效果。
不过这种方式在考虑用户喜好多样性方面,表现不足。
在电商场景下,用户喜好往往是多样性的。如果都转化成固定的vectors,那么模型的拟合能力就会受限。
其次,用户在点击某个物品时候,只是和部分历史行为相关,而不是全部。作者的这个想法也是受NLP里attention机制的启发。
比如文章中的例子:用户更有可能点击游泳镜,因为曾经买过泳衣。哪怕最近的一次行为是在购物车里放了一本书。因此作者提出,对于用户的历史行为应该给予不同程度的attention。
文章主要的观点:
- 学习用户的历史行为喜好,来构建网络,而不是固定大小的vectors来表达
-
为了减少计算量,提出了自适应的正则,只针对非0feature的的部分mini batch做正则计算
- 使用不一样的的激活函数,PReLU和Dice
advertising system in Alibaba
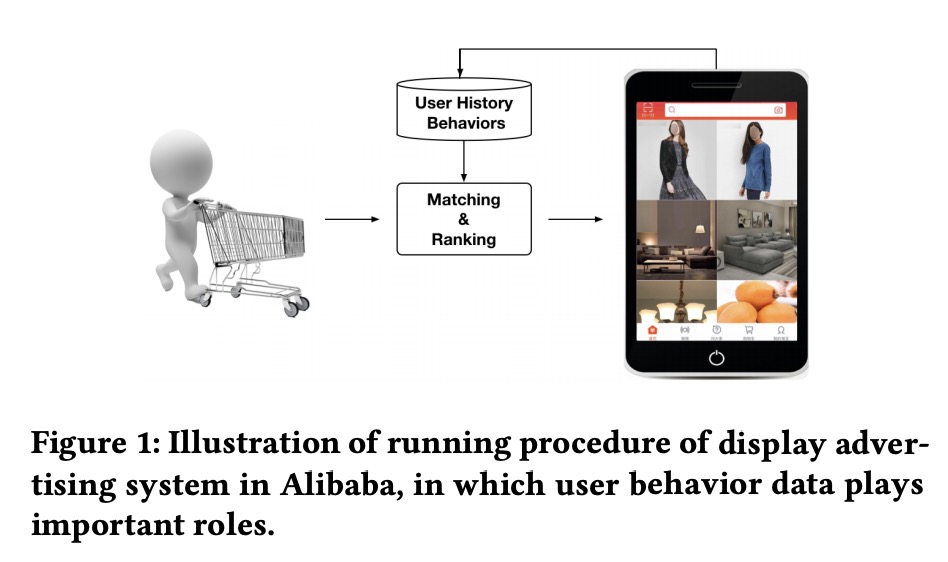
在阿里巴巴的广告系统中,这里分为2个部分:
stage 1 :根据协同过滤产生一些候选集合
stage 2 :ranking stage,对候选集预估CTR
Feature Representation
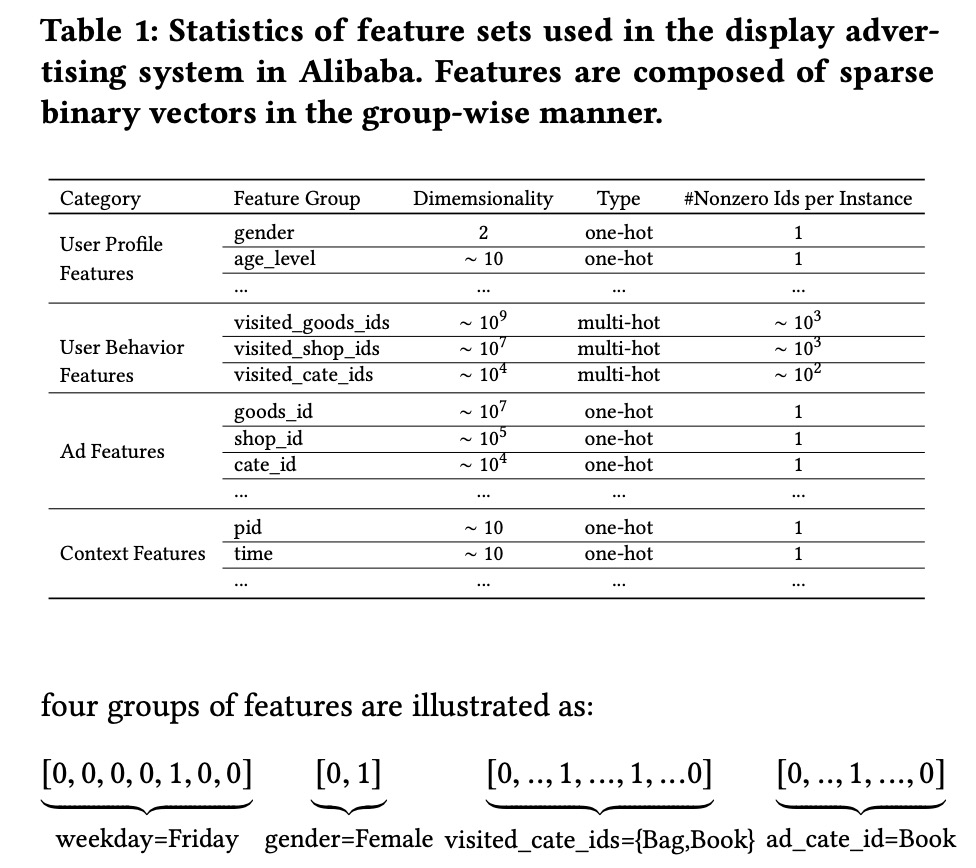
输入特征主要以 one hot encoding 和multi-hot encoding来表示。
Base Model(Embedding&MLP) 、Deep Interest Network
上图中左边部分是Base Model(Embedding&MLP)结构,右边是DIN的网络结构。
2者比较,DIN多了个activation Unit 。它的输入为用户历史行为相关的Goods vector和Candidate Ad vectors。用来学习用户历史行为与候选集合的关系。
activation Unit的输出:
\[v_U(A)=f(v_U,e_1,e_2,...e_H)=\sum_{j=1}^{H}a(e_j,v_A)e_j=\sum_{j=1}^{H}w_je_j\]通俗的解释,就是在用户行为\(\{e_1,e_2,...e_H\}\)和candidate ad A 的情况下,对于历史行为部分,给予不同的w,类似于NLP里的attention weight。不同之处在于,这里\(\sum_{j=1}^{H}w_j=1\),这里的输出也没有加激活函数。
Mini-batch Aware Regularization
上文提到了这篇paper提出了自适应的正则,那么与一般的正则有何不同,可以结合公式一起来看看
\[L_2(W)=||W||_2^2=\sum_{j=1}^K||w_j||_2^2=\sum_{(x,y)\in S}\sum_{j=1}^{K}\frac {I(x_j\neq 0)}{n_j}||w_j||_2^2\]因为输入的特征往往是稀疏的,大多数的特征为0 。也就是这里的\(I(x_j\neq 0)\)对应的就是特征j的非0部分。只关注非0部分,减少计算量。
Data Adaptive Activation Function
关于激活函数,不同以往的ReLU,这里提出了PReLU
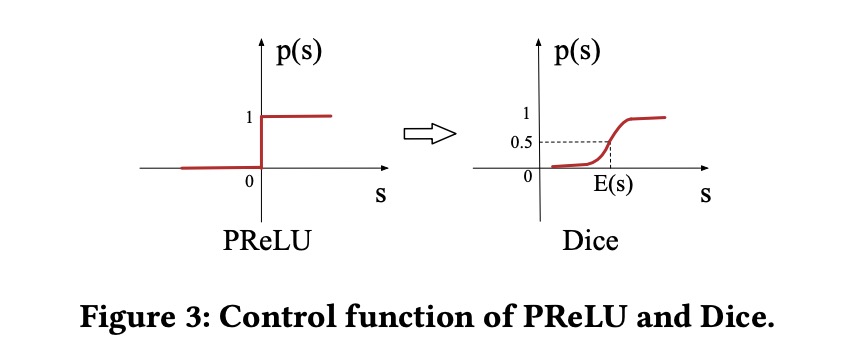
左图的Dice,也就是泛化的PReLU,不过Dice 也考虑输入数据的分布情况,也就是图里的E(s)。
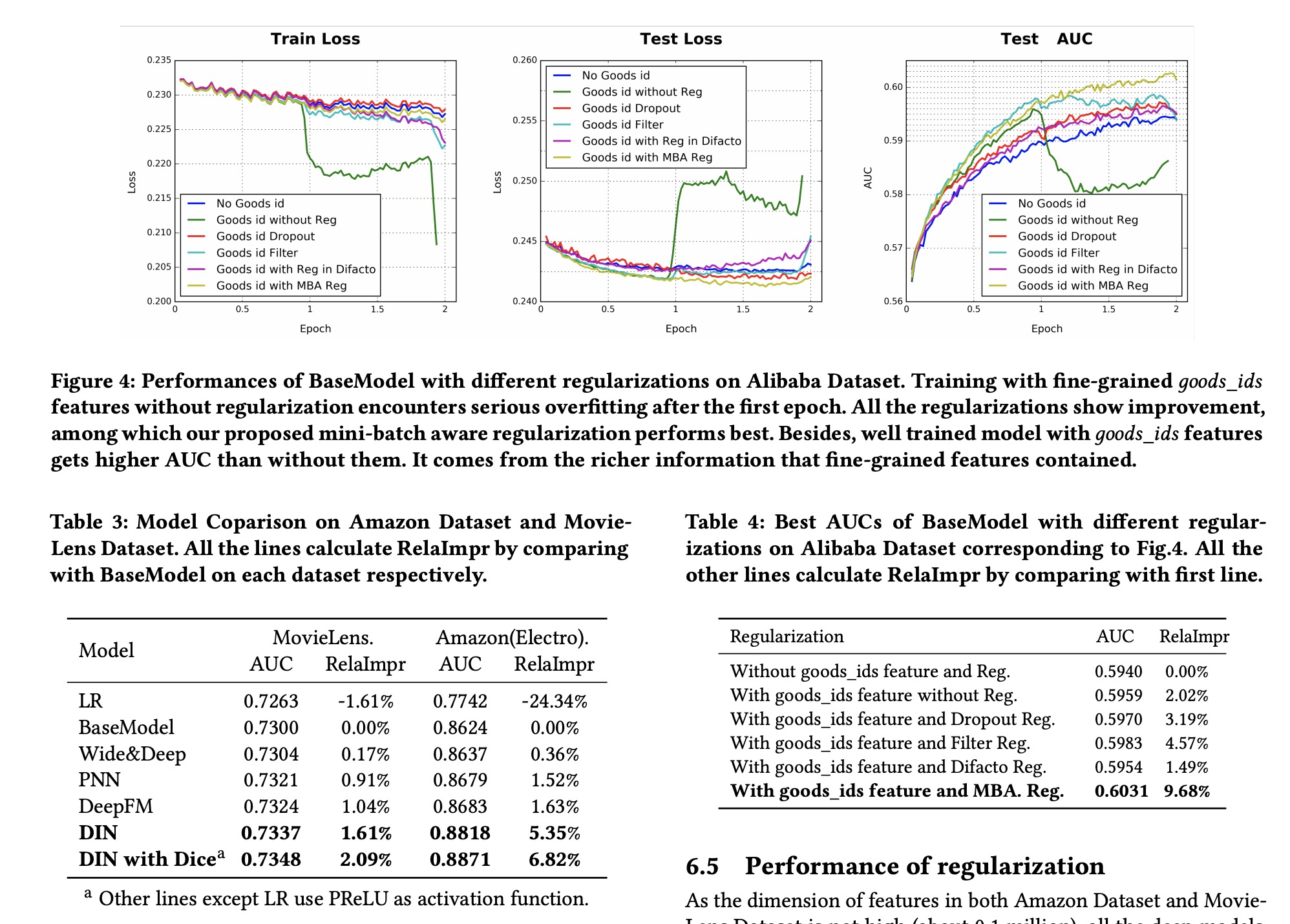
最后作者列出了很多实验表现结果。
REFERENCES
Deep Interest Network for Click-Through Rate Prediction